Charla «Automatizar para Innovar» en FLISoL CABA 2023
index | about | archive | charlas | docs | links
dot |
git |
img |
plt |
tty |
uml
Presentación
Slides vs Debian12
eee, y anoche a las 12hs estaba en la disyuntiva…
si hacer los slides para la charla (siempre la última noche) o
instalar Debian 12 3
Elegí instalar Debian 12, porque tenía ganas, este eee y en realidad porque no me andaba antes la salida HDMI así que fue una buena decisión porque ahora podemos ver, esto…
…y en parte también porque no quería mostrar solamente slides estáticos sino que quería mostrar un poco, algo en vivo.
Ansible Expertise
…eee vamos a intentar de que la internet nos acompañe, este y más que nada lo que quería comentar brevemente…
Un poco la experiencia de uso de Ansible 4 que tenemos en
gcoop.
Y que nos ha permitido innovar gracias a que automatizamos un montón de tareas.
Caso de Éxito
En eso, el caso de éxito que venimos mostrando, es el proceso de …
Esperen que me ande esto… arrghh… Toqué el zoom y ahí no me anda
nada ahí, CTRL+F5 ahí, está!
Bueno, el Banco Credicoop 5, tenía todas las Filiales, es
decir 300 Filiales en todo el país, con 3000 puestos de trabajo
usando tecnología obsoleta, «Ventanas 2000» se llamaba lo que usaban y
bueno, había que pasarlo a GNU/Linux y para hacerlo, esteee…
Bueno el Banco vino a gcoop, que ya somos proveedores de ellos desde hace rato.
…y la idea era cómo hacer esa migración, ese proceso de migración, o
sea, si uno dice Instalar SoftwareLibre, como lo pueden hacer acá en
el InstallFest 6, es como…
Si, bajo una ISO, lo pongo en un pendrive, lo pongo en una compu,
ENTER, ENTER, ENTER y un rato y ya está!
Bueno; es una versión simplificada! Digamos!
Después hay otros conflictos, a nivel usuario final, tenes problemas con el driver de video, con el driver de la red, con el driver de sonido, con la performance…
Con un montón de cosas. Pero en la relación de 1 persona con 1
máquina, será más o menos tiempo, lo solucionas!
AWX
Ahora si vos tenes muchos equipos, como es en el caso del Banco, la
migración fue de 6300 puestos de trabajo, esto es el Banco y es
todos los equipos que administramos desde una sola virtual, que se llama
AWX 7 y que anda por acá en el centro, es esta griscecita que
esta por acá, ese equipo, solo ese equipo controla 6300 equipos!
Y qué es lo que controla? Es bueno, qué sistema operativo se instala cómo se configura ese sistema operativo, qué servicios se instalan, cómo se configuran esos servicios, si es necesario reiniciar un servicio, si es necesario conectar ese servicio con otro servicio, en fin cualquier operación que tradicionalmente se hacía a mano ahora se hace de manera automatizada, es decir, nadie mete mano en los equipos, les cortamos la mano a les SysAdmines, este, porqué? No por mala onda!
IaC
Si no porque cuando vos tenés muchos equipos, es muy difícil que todos te queden iguales, para que te queden todos iguales, lo que tenés que hacer es automatizar todo lo que puedas, para que sean reproducibles, si se rompe un equipo yo tengo que poner uno en las mismas condiciones que estaba antes, para poner algo que está en las mismas condiciones que estaba antes, como hago?
Tengo muy buena memoria o tengo código versionado?
Infraestructura como Código 8, que ese código va a poder
regenerar ese equipo, este una y otra vez, o corregirlo en caso de que
sea necesario.
nerdearla
Hay una charla más completa sobre esto que la di el año pasado en
nerdearla 9 y que los invito a verla en el canal de
nerdearla!
…O en mi sitio osiux.com
SoftwareLibre
Utilizamos todas herramientas libres, nos apoyamos fuertemente en
Ansible, trabajamos con GitLab, AWX es el orquestador gráfico de
Ansible que permite que varias personas operen y hagan, disparen las
ejecuciones de estas automatizaciones, sin saber de código, simplemente
haciendo unos /clics/.
Integramos con un AD (ActiveDirectory 10) la parte de los usuarios, trabajos con FreeIPA 11 que nos permite hacer esa integración de usuarios de «Ventanas» a usuarios Libres, trabajamos con Debian y con una distribución basada en Debian también, este…,
Y bueno, esto tardamos 4 años en hacerlo, esta funcionando, obviamente
todos los días surge algo, y hay que ir corrigiéndolo, pero bueno para
sintetizar…
IDRAC + PXE + Debian NetInstall + Proxmox
Esta AWX que obtiene el código, de lo que tiene que hacer, cada tarea
que tiene que realizar, eso se conecta, por ejemplo en el caso de los
servidores a la iDRAC 12 que es el servidor del servidor, la
computadora de la computadora, y le dice, configurá los discos de esta
manera, creá el RAID, particionalo, todo lo que haga falta, eso
después lo reinicia y dispara la ejecución de un servidor PXE 13
que toma la imagen de un Debian NetInstall que se autoinstala, es
decir que no hay intervención del operador, se configura y lo deja
preinstalado para que después el operador dispare un workflow que
lanza la ejecución y la instalación de un Proxmox 14, para
que haga la virtualización y después eso dispara la ejecución de la
creación de 10 virtuales, diferentes, con distintos servicios y para
eso se apoya en otros equipos que están dentro de la red, que lo que
hace es caché de caché de caché para que esto funcione a lo largo y
ancho de todo el país.
CI/CD
Eso esta totalmente automatizado y en la instancia de Producción
cuando hubo que migrar todos los puestos de trabajo, cuando se llevaron
esos servidores, hubo que configurar todos esos puestos y en algunas
Filiales, no sé, tenés 60 puestos de trabajo y tiene que salir
funcionando, no importa si ese puesto de trabajo esta, no sé, en un
gerencia, en una secretaría, o en una línea de cajas, es el mismo
sistema operativo libre, y de hecho si tuvieras la urgencia podés
sacarlo, del puesto de recepción y ponerlo en una línea de cajas y tiene
que salir andando y si se rompe, lo tirás y ponés uno igual, y mandás a
deployar desde CasaCentral a no sé, Salta o cualquier lugar del
país.
AWX Deploy
Cómo se dispara esto? Bueno, vamos a ver si me anda…, en el Banco soy ogomez no soy osiris, si me acuerdo mi contraseña…
Este sería el AWX de Desarrollo que tenemos, y básicamente lo que se
ve es un panel donde están las distintas opciones, las ejecuciones que
se estuvieron realizando, y acá las plantillas que se usaron
recientemente, por ejemplo se ejecutó wst_bra que es lo que permite es
hacer un escaneo de qué puestos están encendidos en la red y un
workflow de Proxmox que crea máquinas virtuales, podemos ver, ahí lo
Verde es esta todo bien, lo Rojo esta todo mal, pero se puede volver
a ejecutar hasta que dé Verde, una y otra vez!
Workflow
Por ejemplo, tenemos un workflow que se inicia y dispara, un workflow que dispara otros workflows, y es de la máquina virtual de Ansible, la del Servidor FTP, la del servidor PXE, la del servidor de Log, la del servidor de GIT, del servidor de Impresión, el servidor de CDN, el servidor de la caché de APT y el FileServer, y cada uno de estos workflows, si los miramos, vamos a mirar una tarea completada, esta por ejemplo, podemos entrar, acá dio todo en Verde y como ven se ejecutaron todas en paralelo.
Si vemos aquí, este nodo de workflows tiene a su vez, más tareas, y
esta, la primera es, lo que hace es configurar cloudinit, que es algo
que nos ayuda a configurar las maquina virtuales, establece la
configuración de apt.
La configuración de lo que es el servicio de esta VM en particular, y le aplica criterios de seguridad, entonces eso es muy importante, digamos así como escucharon por ahí hablar de DevOps 15, también esta DevSecOps 16, que es cómo garantizo la seguridad de un equipo, bueno todas las políticas tienen que estar versionadas en código, y se tienen que volver aplicar una y otra vez para asegurarse de que este todo bien.
log
Puedo entrar en el detalle, de la ejecución, de cada uno de estos nodos y ver el log de salida.
Este log salida es exactamente lo mismo, que si vos ejecutás Ansible desde la línea de la consola con un Playbook, es lo que te va a devolver, el criterio de color es: Verde esta todo bien, Rojo, error, esta todo mal, este.. Celestito es algo que se ignoró y puede ser un error inesperado que es posible que suceda y uno lo puede ignorar, Naranja es algo que cambió, es decir cambió el estado, y a ver si podemos ver algo acá, que se entienda…
Ahhh… Un poco lenta la máquina, bue, o soy yo… También…
Este log, el resultado en este caso es un JSON, pero puede ser una
salida standaroutput común y bueno acá lo que estaba haciendo es
testeando la configuración de cloudinit, vamos a mirar algo más en
detalle, por ejemplo acá, vemos algo en Naranja que cambió y es este
archivo cloud.cfg
…tiene una expresión regular, acá lo que estaba buscando era
esta línea que dice manage_resolv_conf que me tengo que asegurar que
esto este en una configuración en un archivo en 3000 equipos, sino es
de manera automatizada, no puedo garantizar que esto este en esas
condiciones, es decir solo aplicando permisos no es suficiente, porque
las personas nos equivocamos, cometemos errores, pero por sobre todo por
más que tengamos buenas intenciones, a veces aplicamos una mejora y esa
mejora no la versionamos, no es persistente dentro del equipo, entonces
se reinicia el equipo y se pierde esa configuración, entonces caemos con
el famoso que raro! Que no anda!
A veces te anda, a veces no!, proba con reiniciar, bue…
Para evitar todo eso tenemos esta herramienta que nos permite, publicar código y deployarlo, vamos a ver ahora otra cosa…
Esto es… Espera a ver si me anda…
Parte de la charla lo que quería mostrar también, es…
Hay una serie de scripts que fui construyendo con BASH que es lo que siempre tengo a mano.
awx-cli
Que básicamente son scripts bash que lo que utilizan es el cliente
de consola de AWX, es decir AWX lo puedo usar de manera gráfica, que
esta pensada más a nivel operador para que dispare ejecuciones…
O a nivel de consola y como hay muchas posibilidades y comandos, para
automatizar el uso de la consola hice unos scripts que simplifican esa
tarea porque son muchos comandos y asumen un montón de valores por
defecto, pero digamos si yo quisiera lanzar un comando, en un equipo y
no tengo ganas de ir a la interfaz gráfica, loguearse en AWX, ir la
cantidad de saltos que son como 15 saltos para poder hacer algo
efectivamente, bueno podés tirar un oneliner, que diga…
Bueno conectate, el awx-cli se conecta al servidor AWX y le dice
bueno, ejecutá este trabajo, con estos comandos, con este límite, y
devolveme la salida, la ejecución que disparo desde la consola, queda
almacenada en AWX, entonces alguien puede estar monitoreando en AWX
gráficamente y ver todo el detalle, esto que me garantiza, que tengo
trazabilidad sobre todas las operaciones!
No hay problema con romper algo, cuando alguien rompe algo, lo que queremos es evidencia, para saber que sucedió y cómo corregirlo, porque si alguien entró, digamos por SSH, de modo oscuro que es, nadie esta viendo esa salida, no vamos a saber que sucedió, esto es lo interesante, no hay problema con romper, si lo rompemos, esta registrado en el log lo que pasó, y lo podemos arreglar, si no sabemos que pasó es muy difícil y perdemos tiempo en el diagnóstico.
Entonces para simplificar la operatoria, hicimos una serie de scripts,
hay un montón, o sea son más de 200, que nos permitieron simplificar
el Desarrollo para hacer esto.
A ver si me funciona…
Tengo un error acá, esto es… mmm…mmm..
Como tenemos varias instancias de AWX, tenemos una de Desarrollo,
donde podemos jugar tranquilos, sin romper mucho, sin mucho daño…
Tenemos una de Staging, y tenemos una Productiva, entonces a veces
yo tengo que pasar de una instancia a otra, bueno entonces ya tenemos el
primer comando que es awx-config, le digo el entorno y eso va a
definir, una URL con ciertos túneles, el usuario, y me va a decir, che
ya estas llegando a este servidor de Desarrollo y con estas versiones
de AWX, del ansible-tower-cli 17, y de Ansible en si.
Yo podría decir, desde acá, eee…
adhoc
Por ejemplo, awx-adhoc-shell 18 que voy a entrar a
un equipo y que voy a tirarle un comando, el inventario le digo wst
que son las WorkStations y le voy a poner un límite, que es el lugar
donde podemos romper tranquilo, que es Desarrollo y después le puedo
decir el comando, por ejemplo, voy a hacer algo leve que es el uptime,
funciona? Vamos a ver, si tenemos suerte…
Los WARNINGS los ignoramos siempre :P no importa esta todo
violetita, bueno…
Rojo esta todo mal, Rojo son los equipos que no llegamos, dice UNREACHEABLE…
No sé porqué no llegamos, puede ser que estén apagados simplemente, o puede ser problema de Firewall u otra cosa…
Pero si llegamos a un equipo acá, y nos contestó y nos dice, bueno esta
arriba hace 32 días, esta operativo
Tiré un comando muy tonto, pero bueno, terminó la ejecución y el Job dice que falló porque la tarea la estoy tirando en todo el inventario con varios equipos, entonces yo podría, decir, che bueno…
Supongamos a que a mi no me interesa, ese equipo 662, no lo quiero ni
ver, bueno le puedo decir host-disable
No queremos ver ese WARNING, así que lo deshabilitamos y ahora ese equipo esta deshabilitado, al estar deshabilitado, nadie puede operar sobre él…
Y vuelvo a tirar la misma tarea de antes, en el inventario wst tengo
3000 equipos, tengo un grupo que es Desarrollo donde ahí puedo
romper tranquilo, vuelvo a tirar la misma tarea, así que ahora tengo la
ejecución de 2 hosts, uno falló, el otro salió bien.
Esto que ejecuté desde la consola, digamos, modo Hacking oscuro, si voy al AWX, a Trabajos, tengo el registro de las tareas que se lanzaron, veamos la última, y ahí me dice, bueno, quién la inició, cuándo, con qué parámetros, o sea queda el registro completo de todo lo que se hace en un equipo.
Y esto es en función de la cantidad de espacio que tengan, puden
almacenar, no sé 10 años de ejecuciones sobre un mismo equipo, sobre
3000 equipos, sobre 6000 equipos o todos los equipos que tengan y
que necesiten.
Y acá bueno, es un poco más agradable la salida, pero es básicamente la
misma, hago CTRL+F5 y obtengo más datos, se actualiza, esta un poco
lenta la Internechi, vamos a mirar acá, esta salida, lo puedo ver como
un JSON, como salida standard o si tengo un error, la salida de error.
Bueno, como funciona esto, simplemente tiré un comando aislado.
Playbook
Ahora si yo quiero trabajar algo, más permanente, por ejemplo, vamos a ver, en una Workstation como se hace, cómo se actualiza una Workstation
Pregunta, el comando que tiraste anteriormente, es un comando que esta en la consola del AWX, es un comando local, dentro de AWX o…
No, es un cliente que esta instalado en mi máquina, que se conecta por
un túnel ahora detrás de una VPN y llega al servidor, por medio de la
API de AWX, entonces ya el cliente te maneja, vos le podés hablar
directamente a la API desde otra cosa si quisieras, respetando la
API, es una API REST, lo interesante es que te devuelve todo el
resultado completo y te mantiene el registro, no es que lo tienen
aislado.
La ejecución que hago, no es solo para mi, es en el servidor y todo el mundo la puede ver, digamos, especialmente, Auditoría!
Bueno, esto es un playbook, esto es un playbook de actualización de
una Workstation, lo se hace es definir variables, de qué es el
comportamiento que espera, hay tareas, pero antes de las tareas, hay
pre-tasks, pre-tareas, hay algo que se llama roles te también se
pueden usar y básicamente de esta manera uno va construyendo…
Todas las tareas que uno quiere que se realicen en un equipo, por ejemplo, acá tenemos un fix que es, que…
Usamos algo que se llama autofs 19 que permite montar de
manera automática un filesystem cuando se inicia el equipo y bueno,
teníamos un bugcito y lo básico de ansible cada vez que hace una
tarea es que más allá de la definición de tarea, lo importante es
cuándo se va a ejecutar esa tarea, siempre conviene poner
condicionales, es decir cuando está definido que haga esto y está en
true, bueno hacelo, sino no
Si vemos esa tarea, básicamente lo que esta haciendo esa tarea, bueno se fija que existan los archivos de configuración, en caso de estar definido, restaura unos archivos de configuración que hacen falta y reinicia el servicio.
Entonces para reiniciar un servicio remotamente, la tarea es tan
simple como, esto básicamente, un nombre que es un texto, el módulo
servicio (service), en name le pones el nombre del servicio, que
puede ser cups que puede ser cualquier otro, acá es autofs y el
estado que querés, en este caso que este reiniciado (restarted),
si el servicio no estaba corriendo, bueno lo va a iniciar, en este
caso.
Entonces, de esta manera, vos podés decir que bueno todos los equipos, querés reiniciar el servidor de impresión y lo podés hacer a todos juntos.
Y cuando lo ejecutes vas a tener la salida de eso, en el AWX.
Producción
Ahora vamos a mirar una plantilla, por ej. vamos a mirar algo interesante, vamos a entrar a Producción un ratito, pero no vamos a romper nada, lo prometo, no soy osiris, y esto, acá, bueno acá casi DANGER metemos la pata.
Si voy a inventario, por ejemplo vamos a ver el wst que les
comentaba…
Acá en servidores, vamos a ver, tengo muchos servidores…
Los equipos los tenemos identificados con el número de serie que esta dentro del mother, así sabemos que son esos equipos y no otros y por ej.
Elegí un equipo al azar, y ahí me dice, cual es su IP, cual es su MacAddress, cual es su hostname.
Lo que hicimos, es que los equipos todo el tiempo, que cambian su IP le avisan a AWX y actualizan los datos, entonces están siempre rastreados.
Un equipo puede pertenecer a uno o más grupos, en esos grupos, uno define las variables que quiere que lo afecten.
Y podemos ver el historial, por ej. de este equipo, en tareas completadas, qué se hizo, cuándo y quién lo hizo y tenés todo el historial de ejecuciones, de todas las tareas que se le hizo, entonces por ej. acá no tengo el detalle, vamos a expandirlo, ahí…
Bueno, tenemos en Verde y en Rojo, por ejemplo, este WoL es una plantilla que lo que hace es prenderlo remotamente, si el equipo esta apagado, venís acá y lo prendés, podés prender uno o podés prender todos los equipos al mismo tiempo o de a grupos.
Acá tuvo una actualización, a la versión 1.6 y de hecho falló y
seguramente más adelante, después lo corrigieron, pero si querés ver
porqué falló la actualización de ese equipo, tenes el historial, y vamos
a ver acá, un poco más en detalle…
Bueno el equipo que falló acá, es ese que esta allá y esta en Rojo y pero esta en un ejecución donde el límite había sido toda una Filial, o sea, esta en un grupo de muchos más equipos que se estaban corriendo, así que a esta escala, uno trabaja los equipos no como mascota sino como ganado.
Bueno, hay un montón y ahí hay uno que, después vemos que le pasa, lo que importa que la mayoría funcionen, y fijense en ese resumen…
Dice la cantidad de tareas OK, en la mayoría que esta en Verde, dice
7 tareas que tenía que hacer y las completaron
La segunda columna dice las tareas que cambiaron
La tercera UNREACHEABLE, que es este equipo, que no llegó, no es que
falló, ni siquiera llegó al equipo porque, no sé, estaba apagado, se
aflojó el cable de red, no sabemos, no importa ahora eso, pero esta
claro porqué no se actualizó.
Las tareas que fallaron, las tareas que se saltearon porque no era necesarias hacerlas…
Y si voy un poquito más arriba, ahí tengo cada una de las tareas que se
fueron realizando, por ej. en este equipo, este que termina en MNC, la
plantilla era actualizar, esperen a ver si me sale esto, esta plantilla
era actualizar la versión 1.6 y en el caso de este equipo en
particular, acá el mensaje es «ya está actualizado», entonces, no hay
que actualizarlo!
Esta bien, dio Verde, Verde es como tienen que estar, como se diseño que esté.
job_template
Porque cuál es el principio de Ansible, uno no puede controlar el estado de los equipos, uno lo que puede hacer es llevarlos a un estado conocido, a un estado que uno quiera.
En todo caso si todo eso falla al intentar llevarlo, uno lo que puede hacer es volver al estado anterior, y ese estado anterior puede ser volviendo a una imagen original o ejecutando la versión anterior de la plantilla que se definió para eso.
Ahora bien, para …, tenemos un montón de plantillas o job_templates
que hacen un montón de cosas en diferente equipos, bueno, hay un montón
de tareas, bueno voy a salir de acá, entonces hay que hacer plantillas.
Cómo se hace una plantilla, estamos en Desarrollo, voy a plantillas, digo Nueva, plantilla de trabajo, le ponemos nombre, una descripción, va a ser una plantilla de ejecución, le decimos, che esto va a ejecutar en este inventario, que va a ser el de las Workstations, le digo Seleccionar, OK, le digo que proyecto…
Entonces voy a elegir el proyecto, a ver voy a elegir uno que no haga mucho daño, este, ahí elijo el playbook que tiene ese proyecto.
Le tengo que definir las credenciales con que se va a conectar AWX a ese equipo o grupo de equipos.
Le puedo poner un límite, ahora le voy a poner un límite y además le
puedo decir que pregunte, re-pregunte el límite en momento de
ejecución.
El nivel de log, si quiero o permito en realidad que esta plantilla se puede ejecutar al mismo tiempo más de una vez, le tengo que decir que, habilito concurrentemente y acá abajo le podría poner variables adicionales, que quiero que las tome en el momento de ejecución, que esas variables adicionales lo que harían es, sobreescribir los valores originales de las variables, no es recomendable, pero bueno a veces falta hacerlo.
Luego digo Lanzamiento, para ejecutar, yo definí un límite, ahora me
pregunta, vamos a decirle la 145 , le dijo ejecutá, digo Lanzamiento,
ahí es la instancia de verificar «Está seguro lo que va a hacer», yo le
digo todo que sí, y ahí va a disparar la ejecución, esta ejecución no la
esta disparando desde mi máquina, la esta disparando desde el servidor
de AWX, al servidor de destino.
Y lo que hace AWX es se conecta vía SSH a ese equipo, para poder conectarse hay que definir las credenciales antes, y ejecuta las tareas que tenga este playbook.
En este caso lo que va a hacer es instalar un script que lo que va a
hacer es ping a ciertas IPs, y va a guardar en el log ese
monitoreo para saber si no hay pérdida de paquetes por ej. en este caso,
lo define en el cron, lo reinicia, y lo deja operativo, o sea acá
terminó dice correctamente (successfull), vamos a mirar alguna
tarea, por ej. esta, que básicamente define una tarea en el cron y
esto es importante…
Porque cuando uno tiene muchos equipos, si define una tarea en el cron
de un equipo, después se olvida que lo hizo y después por algún motivo
pasa algo en ese equipo y después de 3 días… Ah cierto que en el
cron, habíamos puesto que se reinicie a las 2AM y nadie se acuerda
de eso, bueno, es importante acá que lo podés hacer con un rol, podés
definir las tareas versionadas y eso se aplica en el cron en todas las
máquinas que hagan falta, porque a veces, te dicen al otro día, che hay
una que no anda a veces, el a veces, porqué el a veces, no sabemos, pero
bueno la apagaron y cambió algo.
Bueno acá queda registrado y es muy simple de definir.
Ahora para hacer toda esta cantidad de plantillas, era como mucho trabajo, no?
Bueno a mi por lo menos no me gusta hacer clics, me gusta usar la consola, y entonces dije bue! Esto se tiene que hacer de otra manera!
Entonces, ahí es donde viene nuestro amigo GitLab a ayudarnos con la
CI, vamos a buscar algo reciente, que sirva de ejemplo…
Pregunta: podés ver qué plantillas se ejecutaron sobre cada equipo?
Respuesta: Si, podés ir del lado tengo plantillas y quiero ver en dónde se ejecutaron o puedo ir al equipo y ver qué se le ejecutó.
Tenes las 2 visiones, pero cuando tenes muchos equipos, tenes a hacer
un inventario dinámico y entonces puede ser que a veces pierdas, o sea
esta la información pero esta como en 2 universos separados y eso es
difícil de relacionar.
Acá yo tengo un rol, que lo que hace es instalar unas utilidades de un servidor que se llama FreeIPA
GitLab CI
Y para instalar y configurar esto, nada mejor que usar el pipeline de GitLab para saber si nuestro rol cada vez que le agregamos un cambio, funciona y no esta rompiendo algo.
Para poder hacer eso, en GitLab podemos buscar acá un error, esto fue
hace 1 mes y fui yo el que metí la pata, acá me dice, bueno mirá, acá
el GitLab dice está roto directamente, cuando metí el commit ya hice
macana!
Vamos a buscar algo más acá… Que tienen bastante en Verde, a ver algo anterior que sirva de ejemplo, bueno vamos a mirar igual una ejecución exitosa, es decir acá queda…
El GitLab dispara la ejecución, en este caso, para chequear que el rol que yo estoy publicando, de Ansible para que después lo lea AWX, esté en condiciones de ejecutarse.
O sea que no tenga ningún error, hace un chequeo básico, pero también, ahora lo voy a buscar, lo que hicimos es agarrar, que en lugar de ir a AWX y disparar la ejecución o desde mi consola disparar la ejecución.
GitLab se ocupa de ir a AWX y disparar la ejecución y mostrarme la salida, entonces de esa manera que tengo, que cada vez que meto un cambio, GitLab dispara las ejecuciones por mí y yo no tengo que estar mirando que es lo que hace, a lo sumo salió exitoso o salió fallida, me va a llegar una notificación y si están fallidas y esta en un branch yo no voy a poder hacer un merge de ese branch a algo productivo porque esta con errores y no me deja porque es una configuración de GitLab que se pone a propósito.
Y para automatizar un paso más esto, para que no solo lo haga GitLab,
proveer estas plantillas dentro de AWX en lugar de ir haciéndolo a
mano, lo que hicimos son unos scripts que lo que hacen es un
deploy… Y vamos a buscar ahora…, hicimos un repositorio que se
llama awx, que tiene esas plantillas en formato de JSON
Y los scripts que invocan a el cliente de AWX a su vez están versionados en un repositorio en GitLab.
Vamos a mirar un deploy reciente y va hacer el deploy, en este caso primero en un ambiente, primero lo hace en Desarrollo y si salió todo bien lo hace en Staging, Staging es más parecido a Producción, acá tenemos uno, otra vez fui yo…
En realidad fue GitLab, bue, acá… Y acá esta interesante este deploy..
GitLab -> AWX
Acá es: GitLab, tomó un repositorio que se llama awx, donde yo le
envié el código que quiero que se publique en AWX y lo que hace es,
revisa eso, se lo manda al AWX de Desarrollo que es el lugar donde
podemos romper, manda la plantilla y cuando manda la plantilla, yo le
puse…
A ver si se ve un poquito más arriba… Me falla el scroll… A ver…
No me deja ir más arriba, bueno… Acá lo que me dice es…
Algo que le pusimos al deploy es, che, fallá si no encontrás la documentación de esta plantilla, porque si no nosotros, hacemos plantillas y después cuando la quieren ejecutar dicen, qué hace esta plantilla? Y ahí decís, te mando un mail.
Bueno, entonces, ya en el Desarrollo, si yo no estoy haciendo la documentación de esta plantilla, ya esta fallando, esta diciendo, es un recordatorio, mirá que tenés que acordarte de hacer la documentación, y no me va a dejar pasar, hasta que yo haga la documentación…
La documentación después puede decir… Este título… Je je y nada más!
Pero bueno, es un chequeo y es un chequeo básico, pero que funciona.
Ahora vamos a ver, en ese caso no funcionó, más adelante, el primer circulito Verde es, Desarrollo, el segundo es Staging, vamos a mirar que hizo el deploy…
Y acá tenemos… Este… Vamos más arriba… Más arriba… Mucho… Ahí… Bueno…
Esta ejecución… Cuando uno hace un push de código, es..
Se baja las ansible_tools para tener la última versión disponible, se
pasa al branch de Desarrollo, porque estamos constantemente en
Desarrollo, genera las credenciales para configurar el acceso para
GitLab pueda entrar a AWX Desarrollo, con el usuario de
Desarrollo, que le permite disparar ejecuciones
Queda ahí el registro entonces que…
Y fíjense que queda ahí esta el MASKED, se ocultan las credenciales, no queda ningún secreto en el log visible
Dice exactamente con qué versiones se configuró, que branch esta queriendo correr, el pull que hizo para obtener la última versión, y acá lo que esta deployando, en este caso eran unos grupos, entonces se fija que este el grupo, que queremos…
Y en este caso, esta haciendo una actualización de variables, este…
Que esta cambiando unos textos, nada más, algo que podría cambiarlo algo a mano
Lo que sucede es, que este cambio que había que hacerlo a mano, hay que hacerlo en un montón de lugares, varias veces
No se, como… Era… eee…
9 cambios en 3 inventarios por 3 grupos cada inventario, es
muy fácil, aunque hagas copiar y pegar, que en alguno te quede distinto!
Entonces la solución es hacer código y que este código, sea testeado por una herramienta automatizada, digamos que…
No tiene corazón, va a fallar ante el mínimo error, no te va a dejar pasar una!
Y en este caso que esta haciendo cambios de variables, de lo que vos
versionaste, con lo que esta en el servidor de AWX, te va a mostrar un
diff del cambio!
Entonces, si hay algo, que tenía que estar y está en AWX y esta bien que esté en AWX, pero lo editaron a mano y nosotros no llegamos a versionarlo como deberíamos, bueno al menos en el log esta, y vamos a poder ver ese cambio de ser necesario.
En este caso son este… eee… Cambios menores, pero bueno…
El ejercicio de hacerlo una y otra vez de manera automatizada, garantiza la calidad del código que finalmente llega a producción.
Y para que esto llegue a producción, o sea, esto mismo lo hicimos en Desarrollo, y si volvemos a la página anterior…
Ese mismo commit, en el «circulito» que sigue acá, lo hace en stage y stage es más parecido a Producción, porque nadie lo esta operando…
Este eee… Y es casi como deployar en Producción!
Si me da bien en Desarrollo, también me tiene que dar bien en Stage
Y para que pase a Producción, esta ejecución, actualmente lo que hacemos es… Le echamos la culpa a «les SysAdmines»
Si tienen un problema es problema de SysAdmins!
Bueno… Esto no fue Desarrollo, pero es la misma herramienta automatizada, son los mismos pasos!
A veces sucede que nos encontramos que hay diferencias de entorno,
recuerden que es muy difícil, tenemos un entorno con 6300 equipos en
Producción, es muy difícil de reproducir y simular!
Entonces, bueno, pasamos varias instancias y a veces llegan errores, normalmente, lo descubrimos eso y lo corregimos y lo volvimos a pasar por la interfaz de GitLab hasta que dé OK y ahí recién lanzamos la versión a producción.
Esto lo que yo veo como que, es una persona que trabaja por mí en testear, que es algo que es bastante aburrido, digamos…
Y si yo disparo la ejecución, ni siquiera disparo, ni siquiera entro al
GitLab, o sea yo estoy en mi línea de comandos, hago git push y me
voy a hacer un mate tranquilo, me voy, cuando estoy en la cocina,
GitLab me va a avisar, me va a mandar un mensajito «no anda nada»,
fijate que hacés, volvé!
Mientras vos disparas esa ejecución, no te tenés que quedar mirándola, te podés poner a hacer otra cosa, otra tarea al mismo tiempo!
Y después más tarde vas, revisas y vez si pasó, en un equipo de Desarrollo que somos varias personas, es decir, si alguien esta teniendo un inconveniente con una tarea…
Tener una reunión virtual para ver que estaba haciendo, que te cuente lo
que pasó, durante los últimos 3 días, para tratar de entender lo que
esta pasando, es una pérdida de tiempo!
Es mucho más simple ir, bueno a ver cuál fue el Job que ejecutaste, el último, bueno, vas mirás ahí y tenés todo el contexto necesario para saber que hizo, este… Yo…
Mi tarea y lo hago conmigo mismo, digamos no es que no tenga corazón, es…
Tengo mi compu llena de capturas donde digo «ahhh, esto acá esta mal!»
Y lo hago todo el tiempo porque, llega un momento que hay tantos valores que es muy difícil entender
Es muy difícil, ver dónde esta el error, es como todo el tiempo jugando
a las 7 diferencias!
Entonces GitLab te va avisar y te va a tirar, «che acá hubo un error», pero a veces hay que tratar de entender ese error, entonces señalarlo!
A veces, el error es, vos mismo pusiste un valor, que no debería haber ido, pero bueno, llegó, y eee…
Para simplificar esto… Salgo de acá…
Tengo por algún lado… A ver si lo encuentro por acá… Creo que acá… Acá…
Automatizar deploy de AWX con GitLab CI/CD y Ansible Tools 20
Acá hay una simplificación de lo que estuve mostrando…
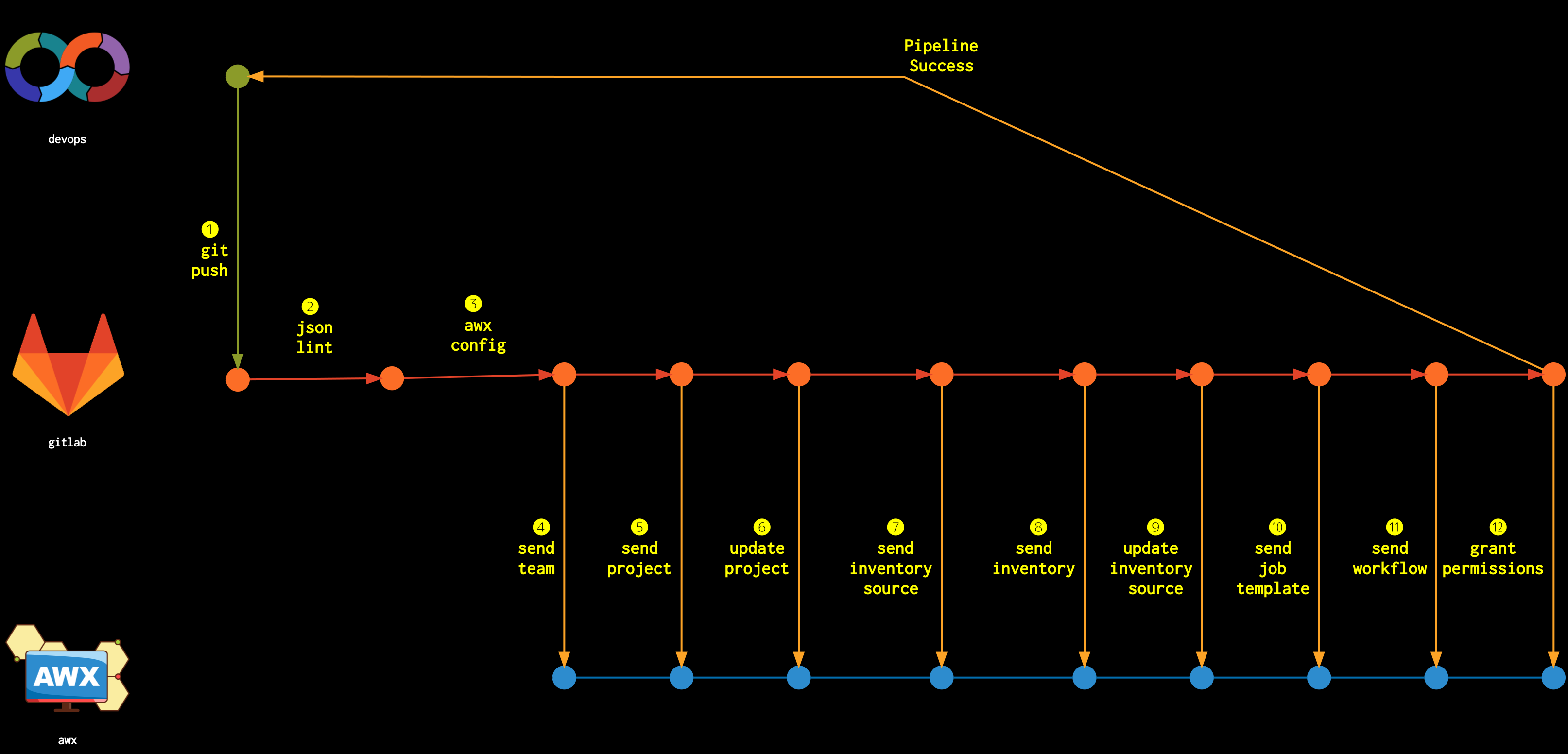
Tenemos a les DevOps, GitLab y AWX
Hacemos un git push de tu entorno local a GitLab
A partir de ahí todo lo que sucede, lo hace GitLab, GitLab habla con AWX, y bueno, primero se fija que los JSONs estén bien, que no tengan ningún error, genera la configuración de AWX, que este bien, que pueda llegar, envía el team, envía el project, actualiza el project, envía el inventory_source, envía el inventory, actualiza el inventory_source, envía el workflow y si este…
Otorga permisos, revoca permisos, y si todo eso salió bien, recién volvés a trabajar vos digamos en eso, no es que no estás haciendo nada, sino que estás trabajando en otra cosa!
Hay un montón de tareas que están automatizadas!
Vos no las tenés que hacer una por una, que es muy probable que te olvides algún paso!
Es decir, que de esto se ocupa GitLab y AWX.
Ansible Tools 21
Ahora esto no es magia, son herramientas que construimos nosotros, que nos equivocamos todo el tiempo, cada tanto hay que corregirlas e ir mejorándolas.
Ese código, este… Esta disponible, en GitLab, los que usan Ansible lo pueden obtener!
Si esto se digna a funcionar… Acá… eee… Para… pa..pa..pa… Dónde, acá…
ansible_tools esta en GitLab, en GitHub, en mis repos personales,
en los repos de gcoop, en Codeberg y no sé dónde más…
- https://github.com/gcoop-libre/ansible_tools
- https://github.com/osiris/ansible_tools
- https://gitlab.com/gcoop-libre/ansible_tools
- https://gitlab.com/osiux/ansible_tools
- https://codeberg.org/osiux/ansible_tools
O sea, está en todos lados, está público todo, y son un montón de scripts que hacen las cosas por uno!
De hecho cuando tenemos que hacer las diferencias, las configuraciones, un montón más de, llamemos burocracia…
Hay documentación automatizada que se autogenera y la hacen los scripts para no cometer errores!
Por ejemplo, yo estoy… eee… Este por ejemplo, este bonito README y
bueno, que tengo esta versión, se hizo tal día, en este archivo, esto lo
hace un script que esta dentro de las ansible_tools.
No hay que estar haciéndolo a mano, si quiero ver, qué incluyó una versión, y qué es lo que tenía… Si vamos a esta por ejemplo…
Entonces, esta documentación también se generó, dice el commit, quién lo hizo, cuándo, qué es lo que trae, qué es lo que cambia, qué permisos otorga, también se hizo, todo de manera automatizada…
La idea es, que todo lo que se tenga que hacer más de una vez, lo automatizemos, no suframos, esteee…
Y lo interesante por ahí es comentar es, que para…
La única manera que creemos posible de llevar adelante este tipo de proyectos, con esta escala, es automatizando, la única manera digamos, o perdemos menos tiempo, digamos…
Después como todo, no es magia, estamos todos los días peleando con algo nuevo, «huy porqué falló esto acá si antes no falló», bueno es ir corrigiendo y mejorando la herramienta.
Pero hay un montón de tiempos que ya no le dedicás más, sobre todo lo mejor es que vos mismo que lo hiciste, al otro día lo podés revisar en el log y no sé qué estaba haciendo acá…
«Cuántas son las veces que falla?»
“Son más veces las que falla, seguro, hasta que sale, pero tenés alguien que revisa por vos, cada punto!
Es decir, por ejemplo, esto, revisa que este la documentación, revisa que el nombre del branch coincida con el nombre de la plantilla y la plantilla apunte a ese branch, que es una pavada, pero que cuando estas escribiéndolo a mano, ponés un punto, una coma, algo ponés mal siempre, das vuelta los números, yo doy vuelta los números siempre.
Y después tenés los errores de producción, que son más graves, tenés una tasa muy alta de errores en Desarrollo, pero una vez que liberás esto, si se hizo de la manera reproducible y repetible y te quedó el log.
Pasó todos los controles en Desarrollo, pasó todos los controles en staging, a producción es raro que falle, puede ser, pero son menos!
Y en mi caso… Tengo el placer acá que tengo varios SysAdmines que
están del otro lado y que yo les digo /«por favor deployen esto!», y yo
les digo, /”deployen la versión tal”_, la 34.5, no sé
Y estas personas se ocupan de hacer eso y me dicen «ya está»!
En el medio hay un log que quedó registrado, que siempre hay que revisarlo, porque puede ser que algún error se escape, pero como que se simplifica la tarea, siempre el mismo proceso, de la misma manera.
Y lo mejor es que con una herramienta libre que la podemos modificar y esta disponible para ustedes si quieren colaborar lo puedan hacer o se puedan inspirar en todo lo que no hay que hacer…!
Bueno, eso creo que esto, no quiero marear más, si tienen algunas preguntas, yo estoy acá!
…en algún momento tenés un punto cero de la máquina…?
Si, en el caso de los servidores…
Quiero ver si lo tengo acá, me parece que no…
La iDRAC de los servidores, crea el RAID y configura la BIOS para
que el próximo reinicio sea por PXE en esta interfaz de red y después
le dice «reiniciate», cuando se reinicia ese servidor, se reinicia en
modo PXE y hay una virtual que tenemos que es un servidor PXE que
dice, «bueno, si aparece un servidor que matchea y dice DELL yo le
mando un Debian», así!
Y es un Debian que lo que hicimos es un preseed que no tiene
interacción humana, osea que es un preseed que automatiza y rompe todo
digamos, reinstala, y busca, de hecho ahora tenemos un inconveniente,
cambiaron el modelo de servidor y lo que antes era sda ahora es sdb
y tuvimos que meter…
Claro, cambió algo ahí y bueno tuvimos que meter mano en ese preseed,
pero bueno, ya lo solucionamos y entonces se reinstala el Debian desde
cero, o sea, si ya tenía, lola, o sea, como agarra la primer
partición, instala todo de cero, un Debian pelado, una vez que termina
ese Debian pelado, te queda…
Cuando se instala ese preseed se dispara la ejecución y se da de alta
ese servidor en AWX y le dice yo soy tal IP y tengo tal MAC y
estoy disponible para deployar!
Después hay un operador que dispara otra ejecución o se se podría automatizar por tiempo, bueno lo esperamos x tiempo y ahí la lanzamos, pero generalmente como son servidores, son equipos caros, hay una intervención, bueno mirar a ver que pasó?
Si salió todo bien dispara la ejecución del workflow, y ese workflow, instala el Proxmox, se baja unas plantillas de unos Backups de VMs, usamos KVM.
Instala un Debian Base de KVM que es el Debian Cloud image, que es bastante standard, el mismo que usan Amazon u OpenStack
Y ahí se le dispara la ejecución de un tercer workflow que instala y
configura los servicios de cada virtual, son 10 virtuales, cuando
termina todo eso, hay un intervención manual porque, ahí nosotros no
tenemos acceso, hay una de esas virtuales que es la VPN, entonces ahí
hay una configuración manual de la VPN, por una cuestión de
credenciales y también por una cuestión de conectividad que en remoto es
difícil de emular.
Y una vez que eso esta y dijeron el servidor está, disparan la ejecución del último workflow que se llama de cierre, y lo que hace es dejar el equipo en condiciones para que cuando se inicie la próxima vez, esté en el lugar remoto, o sea, en Salta, por ejemplo.
Y entonces, toda la operatoria, de sacar un servidor nuevo, de una caja, enchufarle dos cables de red, un cable power, en una hora de tirar cuatro clics, digamos, de ejecuciones, anda!
Hay algunas confinaciones por ahí que hay que hacer, listo tenés un servidor ya vuelto para poner en la caja y mandarlo por el flete!
Así ese proceso, se hicieron 300 veces, entonces se llegaron a hacer
3 servidores al mismo tiempo en paralelo, digamos…
Esto además la migración la hicimos en medio de la cuarentena, así que tenía otras complicaciones!
Y bueno, llevó… La migración en sí, llevó 1 año!
…eee, esperen que tengo por acá, no se dónde… Acá…
Acá hay un poco los datos técnicos, de lo que son los equipos…
Aparecieron 3580 periféricos, pensábamos solo que eran monitores y
computadoras y no, aparenten impresoras, scanners de cheques,
impresoras de tickets, como todas las complejidades y además cada uno
de esos equipos tiene que hablar con un montón de otros equipos que ya
están digamos…
Actualmente para que tengan una idea, es como…
El proceso de por ejemplo de cheques, hay un scanner de cheques, que los scannea y lo manda de la Workstation a un VM que se ocupa de procesar esos archivos y mandarlos a CasaCentral para que en CasaCentral lo puedan verificar con otros procesos, pero automatizados también, y todo eso para que tu cheque se pre-acredite!
Si esa VM de golpe, tipo cae, lo que tienen que hacer es agarrar y mandar los cheques en una camioneta y hasta que no lleguen a CasaCentral, vos no cobras!
O sea, entonces, es crítico que todo este funcionando y además esto se
envía a un servidor en CasaCentral, 300 Filiales lo envían a 1
servidor en CasaCentral que revise esos archivos y que después
coincidan, no, los números!
Por esto mismo, digamos, por esta infraestructura, pasan los cajeros, digamos…
Y hay algunos cajeros que no tienen, son cajeros viejos, que no tienen vínculo directo, entonces el tesorero o alguien responsable dentro de la Filial, va con un pendrive al cajero, hace unas operaciones dentro del cajero y ese pendrive lo lleva a un puesto, que el usuario en ese momento tiene el rol de Tesorero y tiene permiso, le dispara un proceso que procesa esos archivos para que después se envíen a CasaCentral
Una manera Offline, pero porque esos cajeros son muy viejos y bueno
quedaron y hasta que pongan uno nuevo o lugares muy remotos que no hay
mucha conectividad también eso sucede, digamos, pensa que en todo el
país, hay más angosto de banda que ancho de banda, igual toda la
infraestructura tiene redundancia, de mínimo 2 enlaces siempre.
Bueno g.coop.ar nuestro sitio web y bueno acá estan algunos de los
repos que estan libres, no liberamos todo porque no llegamos a tiempo,
pero hay más de 200 repos!
Primero tenés que instalarte Ansible, es otro curso!
Son equipos completos, estan basados en Debian, medio lo que estan haciendo acá, nosotros en muchos equipos lo que hicimos es, construimos el modelo un equipo con Ansible y una vez que se hicieron un montón de pruebas y se dijo ya está bien!
Se hizo una imagen, una ISO del equipo, y se le mandó al proveedor de
los equipos, y se le dijo «bueno, copialo vos de alguna manera en 3000
equipos!»
Entonces ya tienen una imagen base, cuando llegan a la Filial, las
diferencias de versión o algunas cuestiones que son propias de esa
instancia se hacen remotamente y cada tanto se genera una actualización,
que es una plantilla que se ocupa de actualizar de la v1.4 a la
v1.5, pero que eso puede tardar mucho tiempo a veces, por esto que
decíamos del ancho de banda y porque son muchas tareas en un equipo.
Entonces a veces lo que se hace es, si el salto es muy grande, de cambios que hubo, se hace una nueva imagen base y se manda la imagen base y van con un equipo nuevo directamente y reemplazan uno por otro.
Estamos? 2 preguntas más? Si alguien se anima?
Que este chequeando todo el tiempo si hubo un cambio y si hubo un cambio haga un Update, entonces siempre lo tenes actualizado y lo podemos poner a la noche….
Soy yo, te ganaste una careta! Otra pregunta?
Alguien tiene otra pregunta?
Seguro te interesará leer…
- Cómo migrar 6300 equipos a GNU/Linux usando Ansible y AWX
- Automatizar la configuración de la BIOS usando
ansibley HP Linux Tools Filiales GNU/LinuxFLISoL CABA- Ansible Tools
v0.3.0 - Automatizar la implementación de los recursos de AWX con GitLab CI/CD y Ansible Tools
- Usar Graphviz para generar Slides
- Cómo hacer una línea de tiempo con GraphViz
ChangeLog
2024-02-27 09:02corregir tamaño video Charla «Automatizar para Innovar» en FLISoL CABA 20232023-12-19 15:45actualizar KEYWORDS, agregar poster link de descarga de video y agregar link a charla nerdearla en Charla «Automatizar para Innovar» en FLISoL CABA 20232023-12-19 14:05agregar Charla «Automatizar para Innovar» en FLISoL CABA 2023